
Praca magisterska
OPTYMALIZACJA WYDAJNOŚCI SERWERA WWW (fragment pracy)
Wstęp
1. Podstawowe zagadnienia związane z optymalizacją wydajności serwera WWW
1.1. Czas odpowiedzi, a reakcja użytkownika
1.2. Techniki Web Caching’u.
1.1.1. Typy buforów WWW
1.1.2. Bufory przeglądarek
1.1.3. Pośredniki buforujące
1.1.4. Surogaty
1.1.5. Zalety technologii.
1.3. Technologie klastrowe.
1.3.1. Definicja klastra
1.3.2. Klasyfikacja klastrów
1.3.3. Zastosowanie technologii klastrów.
1.4. Architektura serwera WWW – Apache
1.4.1. Architektura w wersji 1.3.x
1.4.2. Architektura w wersji 2.x
2. Środowisko testowe
2.1. Sprzęt i okablowanie
2.2. Zainstalowane oprogramowanie na maszynach testowych
2.3. Wykorzystanie oprogramowanie do testowania wydajności
3. Badanie wydajności środowiska
3.1. Różne architektury maszyn i przepustowości sieci
3.2. Klaster z wykorzystaniem load balancing udostępniający usługę WWW
3.3. Klaster z wykorzystaniem load balancing buforujący zawartość stron WWW
3.4. Wydajność treści statycznej w zależności od konfiguracji serwera WWW - HTML
3.5. Wydajność treści dynamicznej w zależności od konfiguracji serwera WWW - PERL
3.6. Wydajność treści dynamicznej w zależności od konfiguracji serwera WWW - PHP
3.7. Zużycie pamięci w zależności od konfiguracji serwera WWW
4. Podsumowanie
BIBLIOGRAFIA
SPIS RYSUNKÓW
SPIS TABEL
Wstęp
Przeprowadzone w lipcu 2007 roku badania organizacji Netcraft wykazały, że blisko 52.65% wszystkich serwerów WWW działających w Internecie to serwery Apache. Oprogramowanie to stanowi podstawowy element codziennej aktywności użytkowników Internetu. Stał się niezauważalnym artefaktem w architekturze sieciowej. Za każdym razem, gdy internauta dokonuje zakupu książki, rezerwacji biletu, przeglądu wiadomości w portalach, sprawdzaniu konta bankowego, licytacji na aukcji internetowej, serwer Apache jest w to zaangażowany.[13]
Wyzwaniem dla zarządców ośrodków webowych jest zapewnienie szybkiego dostępu i pełnych usług, w miarę wzrastania popularności tych ośrodków webowych, często przy użyciu wciąż tych samych zasobów, gdy dostarczanie zawartości z ośrodka webowego zaczyna być niepokojąco powolne, wizytujący mogą szybko zacząć klikać na stronie konkurencji, oto dlaczego zagadnienia związane w optymalizacją wydajności serwera WWW są tak istotne.
Środowisko testowe
W tym rozdziale zostało opisane środowisko testowe, wybrane maszyny, ich konfiguracje sprzętowe oraz programowe. Pokazano poglądową strukturę sieci, a także opisano użyte oprogramowanie do testowania wydajności serwera WWW.
Sprzęt i okablowanie
Środowisko testowe zostało wybrane ze względu na charakterystykę posiadanego przez Bibliotekę Główną sprzętu, a także z uwzględnieniem różnorodności architektur. Poniżej znajdują się tabele z listą wykorzystywanych do testów sprzętów w postaci komputerów oraz switch’y sieciowych.
Tabele zawierają podstawowe informacje, jakie mogą mieć wpływ na otrzymane rezultaty w wykonanych badaniach takie jak typ procesora, posiadana pamięć, zastosowany chipset płyty głównej, zainstalowana karta graficzna, rodzaj i wielkość dysków twardych oraz rodzaj kart sieciowych. Oprócz takich podstawowych informacji została podana również szacunkowa wartość sprzętu. W przypadku switch’y tabela zawiera informację o typie i producencie switch’a, a także rodzaj zastosowanego okablowania.
KOMPUTER 1 |
|
Procesor | Celeron 2.40GHz |
Pamięć | 512MB |
Chipset | 661FX |
Karty sieciowe | - zintegrowana SiS900 100Mbit |
Karta graficzna | Zintegrowana |
Dyski twarde | - 42GB PATA |
Szacunkowa wartość komputera (brutto) | 1500zł |
KOMPUTER 2 |
|
Procesor | Intel Pentium IV 3.00GHz |
Pamięć | 1.512MB |
Chipset | Intel Corporation 82875P |
Karty sieciowe | - zintegrowana Broadcom Corporation NetXtreme BCM5705_2 Gigabit Ethernet |
Karta graficzna | ATI Technologies Inc Rage XL |
Dyski twarde | - 80GB PATA |
Szacunkowa wartość komputera (brutto) | 3600zł |
KOMPUTER 3 |
|
Procesor | Intel Pentium IV 2.60GHz |
Pamięć | 1.512MB |
Chipset | Intel Corporation 82865G |
Karty sieciowe | - Intel Corporation 82562EZ 10/100 |
Karta graficzna | Zintegrowana |
Dyski twarde | - 36x4 SCSI (RAID 10) |
Szacunkowa wartość komputera (brutto) | 4500zł |
KOMPUTER 4 |
|
Procesor | - Intel Xeon 5110 1.60GHz |
Pamięć | 2GB |
Chipset | Intel Corporation 5000X |
Karty sieciowe | - Intel Corporation 80003ES2LAN Gigabit |
Karta graficzna | nVidia Corporation GeForce 7300 LE |
Dyski twarde | 73x2 SCSI (RAID 1) 15000 obrotów |
Szacunkowa wartość komputera (brutto) | 9300zł |
Komputery, z których zbudowano klaster:
KOMPUTER 5 |
|
Procesor | Duron 1GHz |
Pamięć | 256MB |
Chipset | Apollo KT266/A/333 |
Karty sieciowe | Realtek RTL-8139/8139C/8139C+ |
Karta graficzna | GeForce2 MX |
Dyski twarde | - 40GB PATA |
Szacunkowa wartość komputera (brutto) | 600zł |
KOMPUTER 6 |
|
Procesor | Celeron 2.40GHz |
Pamięć | 512MB |
Chipset | 661FX |
Karty sieciowe | - zintegrowana SiS900 100Mbit |
Karta graficzna | Zintegrowana |
Dyski twarde | - 40GB PATA |
Szacunkowa wartość komputera (brutto) | 1100zł |
KOMPUTER 7 |
|
Procesor | Celeron 2.40GHz |
Pamięć | 512MB |
Chipset | 661FX |
Karty sieciowe | - zintegrowana SiS900 100Mbit |
Karta graficzna | Zintegrowana |
Dyski twarde | - 40GB PATA |
Szacunkowa wartość komputera (brutto) | 1100zł |
Sieć zbudowana jest z następujących elementów:
Elementy sieciowe |
|
Switch dla sieci 100Mb | 3Com 3C16593B SUPERSTACK 3 |
Okablowanie | UTP 5 |
Switch dla sieci 1Gb | 3Com GIGABIT SWITCH 8 10/100/1000 |
Okablowanie | UTP 5E |
Wykorzystanie oprogramowanie do testowania wydajności
Do przeprowadzenia testów wydajnościowych potrzebujemy rozwiązania programowego posiadającego własność generowania ruchu http, gdzie uruchamianych jest wiele procesów, każdy nawiązuje połączenie z serwerem, czeka na odpowiedz i mierzy parametry takiej procedury (czy dostano odpowiedz, czas odpowiedzi), takim rozwiązaniem – programem – jest Apache Benchmark rozpowszechniany razem z oprogramowaniem Apache[12].
AB (Apache Benchmark) pozwala na wielokrotne wywołanie URL i przygotowuje statystyki czasu wykonania. Program wywołuje się z linii poleceń, jego najważniejsze parametry to:
n - ilość zapytań
c - ilość zapytań w tym samym czasie
k - wymusza użycie stałego połączenia - HTTP KeepAlive
g – generowanie statystyk do pliku (gnuplot-file)
Przykładowe wywołanie może mieć postać:
ab –n2000 –c20 -k http://www.przyklad.pl/ab_test.php
W wyniku przeprowadzonego pomiaru otrzymamy:
Server Software: Apache/2.2.3
Server Hostname: www.przyklad.pl
Server Port: 80
Document Path: ab_test.php
Document Length: 362 bytes
Concurrency Level: 20
Time taken for tests: 1.370750 seconds
Complete requests: 2000
Failed requests: 0
Write errors: 0
Keep-Alive requests: 0
Total transferred: 994000 bytes
HTML transferred: 724000 bytes
Requests per second: 1459.06 [#/sec] (mean)
Time per request: 13.707 [ms] (mean)
Time per request: 0.685 [ms] (mean, across all concurrent requests)
Transfer rate: 707.64 [Kbytes/sec] received
Connection Times (ms)
min mean[+/-sd] median max
Connect: 0 0 0.3 0 4
Processing: 4 12 11.2 12 364
Waiting: 3 12 10.9 11 362
Total: 6 12 11.2 12 364
Percentage of the requests served within a certain time (ms)
50% 12
66% 12
75% 13
80% 13
90% 15
95% 16
98% 24
99% 27
100% 364 (longest request)
W otrzymanych danych można wydzielić trzy fragmenty o dużym znaczeniu dla wydajności serwera są to przede wszystkim wiersze:- time taken for tests – czas potrzebny na wykonanie testów
- time per request – czas potrzebny na realizację żądania
- requests per second – liczba żądań na sekundę
Można sformułować następujący wniosek: im niższe są wartości dwóch pierwszych parametrów, tym większa jest wydajność serwera. Z kolei wartość liczby żądań na sekundę powinna być utrzymywana na jak najwyższym poziomie.
Badanie wydajności środowiska
W tym rozdziale zostały opisane przeprowadzone badania wydajności serwera WWW poprzez zmianę wykorzystywanego sprzętu uwzględniającą różne architektury, budowę klastrów czy zmian w przepustowości sieci. Badania objęły również zmiany w konfiguracji aplikacji jak i modułów zależnych oraz samego kodu programów uruchamianych poprzez serwer WWW.
Różne architektury maszyn i przepustowości sieci
Badanie to miało na celu zbadanie jaki wpływ ma architektura maszyny na wydajność serwera Apache. W badaniu wzięły udział serwery o numerach 1,2,3,4. Pomiary zostały wykonane w godzinach nocnych, gdy obciążenie serwerów było minimalne. Do mierzenia wykorzystano wcześniej omówiony program ab z parametrami:
- dla treści statycznej
ab -n 50000 -k -c 100 -g testmasz.txt http://testmasz/test/test.html
- dla treści dynamicznej
ab -n 25000 -c 50 -g testmasz.txt http://testmasz/cgi-bin/test.pl
Przetestowano wydajność architektury dla treści statycznej (HTML) oraz dynamicznej (PERL), a także zmianę wydajności przy zmianie łącza (z 100Mb na 1Gb). Pomiar z wykorzystaniem szybszego łącza został wykonany również dlatego, że w raporcie „Meeting the Connectivity Challenge” z roku 2006 dokonanym wśród użytkowników ponad 2 tysięcy sieci LAN zainstalowanych w 48 krajach podano, że przepływności rzędu 1 Gb/s stają się normą okablowania strukturalnego przedsiębiorstw. Pliki testowe miały taką samą budowę jak przy testowanym klastrze z wykorzystaniem load balancing’u.
Na początku przestawano treść statyczną HTML. Kod strony HTML zawiera tylko kilka znaczników, nie powodując zwiększonego zapotrzebowania na pamięć co by mogło mieć wpływ na wydajność maszyn o mniejszej ilości pamięci.
Na podstawie przedstawionych w tabeli wynikach uwidoczniono, że najlepiej wypadła najnowsza architektura Intela Xeon. Podczas przeprowadzanego testu obciążenie load average nie wykazywało znacznego obciążenia maszyny, natomiast w przypadku starszych architektur takich jak Pentium 4 i Celeron obciążenie osiągało bardzo duże wartości, w granicach 30 i więcej, gdzie już można mówić o przeciążeniu i niewydolności systemu.
Cechą charakterystyczną procesorów Celeron (w porównaniu do procesorów Pentium) jest mniejsza ilość pamięci podręcznej. Przekłada się to na znaczne zmniejszenie ceny takich układów, ponieważ produkcja pamięci stanowiącej cache jest stosunkowo bardzo droga, a także na znaczący spadek wydajności jak pokazują wykonane testy. Stosowanie „obciętych” procesorów klasy Celeron mija się z celem, ilość żądań na sekundę na poziomie 957 wypada bardzo mizernie w porównaniu z pełnym procesorem Pentium.
Tabela 1 - Treść statyczna HTML bez opcji keep-alive
KOMPUTER | KOMP 4 | KOMP 3 | KOMP 2 | KOMP 1 |
Czas testu [s] | 19.132151 | 20.70795 | 21.70495 | 52.217408 |
Odebranych bajtów (całość) | 21067682 | 21057578 | 21057570 | 22550000 |
Odebranych bajtów (HTML) | 8457098 | 8453042 | 8453040 | 8450000 |
Żądań na sekundę | 2613.40 | 2491.18 | 2461.18 | 957.54 |
Czas na żądanie [ms] | 38.264 / 0.383 | 40.142 / 0.401 | 40.342 / 0.411 | 104.435 / 1.044 |
Transfer [Kbytes/sec] | 1075.31 | 1024.57 | 1014.53 | 421.72 |
Źródło: opracowanie własne
Kolejny test to wykorzystanie „dopalacza” w postaci opcji keep-alive. Specyfikacja protokołu HTTP/1.1. zaleca, by wszystkie serwery zgodne z wersją HTTP/1.1 implementowały trwałe połączenia TCP w celu zwiększenia ogólnej wydajności sieci Internet. Domyślnie procesy potomne serwera Apache czekają przez 15 sekund na następne żądanie zanim zamkną połączenie TCP.
W tym przypadku jeszcze bardziej widać różnice na korzyść nowej platformy, bijąc starsze rozwiązania prawie dwukrotnie większą wydajnością, a w przypadku Celerona nawet 6 krotnie przy bardzo nikłym poziomie obciążenia.
Tabela 2 - Treść statyczna HTML z opcją keep-alive
KOMPUTER | KOMP 4 | KOMP 3 | KOMP 1 |
Czas testu [s] | 5.769250 | 10.812041 | 31.928955 |
Odebranych bajtów (całość) | 22904450 | 22880282 | 24328531 |
Odebranych bajtów (HTML) | 8459126 | 8450169 | 8450000 |
Żądań na sekundę | 8666.64 | 4624.47 | 1565.98 |
Czas na żądanie [ms] | 11.538 / 0.115 | 21.624 / 0.216 | 63.858 / 0.639 |
Transfer [Kbytes/sec] | 3876.93 | 2066.58 | 744.09 |
Źródło: opracowanie własne
Przy zmianie łącza z 100Mb na 1Gb uzyskujemy nieznaczną poprawę w otrzymanych rezultatach, ilość obsłużonych żądań w przypadku KOMP 4 i 3 wzrosła o około 300. Tak więc można stwierdzić, że wymiana łącza również może zwiększyć wydajność całego środowiska.
Tabela 3 - Treść statyczna HTML na łączu 1Gbit
KOMPUTER | KOMP 4 | KOMP 3 | KOMP 1 |
Czas testu [s] | 16.788212 | 17.945531 | 50.602515 |
Odebranych bajtów (całość) | 21066419 | 21056736 | 22550000 |
Odebranych bajtów (HTML) | 8456591 | 8452704 | 8450000 |
Żądań na sekundę | 2978.28 | 2786.21 | 988.09 |
Czas na żądanie [ms] | 33.576 / 0.336 | 35.891 / 0.359 | 101.205 / 1.012 |
Transfer [Kbytes/sec] | 1225.38 | 1145.86 | 435.18 |
Źródło: opracowanie własne
Natomiast w przypadku zastosowania opcji keep-alive nie widać już takiej różnicy w przepustowości sieci. Otrzymane wyniki są zbliżone do łącza 100Mbit.
Tabela 4 - Treść statyczna HTML na łączu 1 Gbit (keep-alive)
KOMPUTER | KOMP 4 | KOMP 3 | KOMP 1 |
Czas testu [s] | 5.342025 | 11.145813 | 30.746245 |
Odebranych bajtów (całość) | 22887628 | 22880072 | 24328521 |
Odebranych bajtów (HTML) | 8453380 | 8450000 | 8450000 |
Żądań na sekundę | 9359.75 | 4485.99 | 1626.21 |
Czas na żądanie [ms] | 10.684 / 0.107 | 22.292 / 0.223 | 61.492 / 0.615 |
Transfer [Kbytes/sec] | 4183.99 | 2004.61 | 772.71 |
Źródło: opracowanie własne
Kolejna grupa testów to badanie wydajności przy obsłudze treści dynamicznej z wykorzystaniem niezoptymalizowanego skryptu CGI napisanego w języku skryptowym PERL. W przypadku takiej treści różnice są diametralne, komputer 4 był prawie czterokrotnie szybszy od komputera 3, a od komputera 1 aż 13 krotnie szybszy.
Tabela 5 - Treść dynamiczna PERL (keep-alive)
KOMPUTER | KOMP 4 | KOMP 3 | KOMP 1 |
Czas testu [s] | 35.889384 | 172.690313 | 478.758291 |
Odebranych bajtów (całość) | 18299702 | 17862782 | 19101906 |
Odebranych bajtów (HTML) | 13950558 | 13950000 | 14050000 |
Żądań na sekundę | 696.58 | 144.77 | 52.22 |
Czas na żądanie [ms] | 71.779 / 1.436 | 345.381 / 6.908 | 957.517 / 19.150 |
Transfer [Kbytes/sec] | 497.92 | 101.01 | 38.96 |
Źródło: opracowanie własne
Podsumowując wykonane testy można dojść do wniosków, ze architektura ma bardzo duże znaczenie dla wydajności całego środowiska, gdy nie mamy dostępu do kodów źródłowych programów, zmiana sprzętu na bardziej wydajny jest najprostszym sposobem (choć nie tanim) zwiększenia możliwości serwera WWW. Im bardziej dynamiczne, multimedialne i „ciężkie” strony obsługuje Apache tym zastosowanie dysków SAS z procesorami wielordzeniowymi ma większe znaczenie dla optymalizacji wydajności.
Klaster z wykorzystaniem load balancing buforujący zawartość stron WWW
Badanie miało na celu sprawdzenie jak zastosowanie surgat wpływa na wydajność dostarczania treści do odbiorcy. W tym celu został wykorzystany zbudowany wcześniej klaster z użyciem dwóch skryptów konfigurujących, jeden dla komputera zarządzającego klastrem, drugi dla komputerów pełniących role pośrednika (surogat) w dostarczaniu treści.
Skrypt konfigurujący komputery RS ma postać:
#!/bin/bash
/sbin/route add default gw 10.0.1.254
echo "0" >/proc/sys/net/ipv4/ip_forward
ifconfig lo:197 10.0.1.197 broadcast 10.0.1.197 netmask 255.255.255.255 up
ifconfig lo:197
/sbin/route add -host 10.0.1.197 dev lo:197
echo "1" >/proc/sys/net/ipv4/conf/all/arp_ignore
echo "1" >/proc/sys/net/ipv4/conf/lo/arp_ignore
Natomiast skrypt konfigurujący komputer LD wygląda:
#!/bin/bash
IPV="/sbin/ipvsadm"
echo "0" > /proc/sys/net/ipv4/ip_forward
/sbin/ifconfig eth0:197 10.0.1.197 broadcast 10.0.1.197 \
netmask 255.255.255.255
/sbin/route add -host 10.0.1.197 dev eth0:197
/sbin/ifconfig eth0:197
ping -c 1 10.0.1.197
$IPV -C
$IPV -A -t 10.0.1.197:80 -s rr
$IPV -a -t 10.0.1.197:80 -r 10.0.1.103:80 -g -w 1
$IPV -a -t 10.0.1.197:80 -r 10.0.1.105:80 -g -w 2
ping -c 1 10.0.1.103
ping -c 1 10.0.1.105
$IPV
Surogatą w badanym przypadku zostało wybrane oprogramowanie Varnish będące wysokowydajnym akceleratorem http. Autorzy na stronie projektu podają, że ich rozwiązanie jest prawie 12-krotnie szybsze od popularnego serwera proxy - Squid. Projekt zainicjowany z ramienia norweskiej gazety „Verdens Gang”, głównym architektem i zarządzającym projektem jest duńczyk Poul-Henning Kamp wspierany przez norweską firmę konsultingową Linpro.
Autorzy chwalą się nowym podejściem do projektowania, pisząc, że zrywają z konwencją pisania programów tak jak w roku 1975, gdzie obowiązywał podział na pamięć RAM oraz pamięć masową. Obecnie jądra systemów są tak zaawansowane, że ten podział przestał istnieć i według twórców program nie powinien decydować, jaka pamięć ma być wykorzystywana, to jądro zarządza wszystkimi nośnikami pamięci[15].
Koncepcja programu opiera się na tworzeniu osobnego wątka dla każdego nowego połączenia, jeśli nastąpi przekroczenie z góry ustalonej ilości wątków, takie połączenie oczekuje w kolejce, która również jest ograniczona (ustalana w pliku konfiguracyjnym), po jej przekroczeniu następne połączenia są odrzucane. System został tak zaprojektowany, aby minimalizować czas tworzenia wątku do minimum. Wszystko zależy od jakości implementacji wątków w systemie.
W badanym przypadku akcelerator został uruchomiony z następującymi parametrami:
varnishd -a 0.0.0.0:80 -b 10.0.1.233:80 -n /var/varnish/ -T 127.0.0.1:81 -p thread_pool_max=1500 -p thread_pools=5 –p listen_depth=512 -p client_http11=on -s file,/tmp/,524288
gdzie:
a – adresie oraz port na którym usługa ma oczekiwać na połączenie
b – adres oraz port serwera źródłowego
n – określa gdzie mają być przechowywane tymczasowe pliki
T – adres oraz port interfejsu administracyjnego
s – typ systemu przechowywania danych
p – ustawienie danego parametru (parametr = wartość)
Varnish zawsze odpowiada nagłówkami HTTP/1.1 i nie wysyła (co jest zgodne z HTTP/1.1) nagłówka „Connection: keep-alive” nawet wtedy, gdy klient wysyła żądania z użyciem nagłówków HTTP/1.0 jak to robi właśnie program testujący wydajność ab. Tak więc aby program ab poprawnie działał i dokonywał poprawnych obliczeń czasowych należało nałożyć poprawkę na plik cache-response.c:
zastępując linie:
if (sp->doclose != NULL)
http_SetHeader(sp->wrk, sp->fd, sp->http, "Connection: close");
linią:
http_PrintfHeader(sp->wrk, sp->fd, sp->http, "Connection: %s",sp->doclose ? "close" : "keep-alive");
Wykonano testy dla treści dynamicznej test.pl, tak jak w poprzednim badaniu 50000 zapytań (w tym 50 w tym samym czasie), komenda ab z argumentami miała postać:
ab -n 50000 -c 50 -g testmasz.txt http://10.0.1.197/cgi-bin/test.pl
W wyniku testu otrzymano następujące rezultaty dla i bez opcji keep-alive:
Tabela 11 - Treść dynamiczna - surogata (bez opcji keep-alive)
KOMPUTER | KLASTER | KOMP 5 | KOMP 6 |
Czas testu [s] | 18.227125 | 27.724936 | 27.62181 |
Odebranych bajtów (całość) | 44127577 | 44133173 | 44132492 |
Odebranych bajtów (HTML) | 27902232 | 27900000 | 27900000 |
Żądań na sekundę | 2743.16 | 1803.43 | 1847.60 |
Czas na żądanie [ms] | 18.227 / 0.365 | 27.725 / 0.554 | 27.062 / 0.541 |
Transfer [Kbytes/sec] | 2364.22 | 1554.49 | 1592.55 |
Źródło: opracowanie własne
Jak widać na załączonej tabeli zastosowanie klastera zwiększyła prawie dwukrotnie wydajność całego systemu. Zastosowanie Varnisha dało nadzwyczaj dobre wyniki, porównując do poprzednich testów są one lepsze niż dostarczanie treści statycznej przez sam serwera WWW, a do tego obserwując obciążenie maszyn nie przekraczało ono wartości 5 (w przypadku testu klastra). Porównując różnice w architekturach komputerów 5 i 6 nie widać już przepaści wydajności między Duronem, a Celeronem. Ich wydajność zrównała się.
Tabela 12 - Treść dynamiczna - surogata (z opcją keep-alive)
KOMPUTER | KLASTER | KOMP 5 | KOMP 6 |
Czas testu [s] | 7.591255 | 12.811369 | 12.394445 |
Odebranych bajtów (całość) | 44451778 | 44362645 | 44361728 |
Odebranych bajtów (HTML) | 27901116 | 27900000 | 27900000 |
Żądań na sekundę | 6586.53 | 3902.78 | 4034.07 |
Czas na żądanie [ms] | 7.591 / 0.152 | 12.811 / 0.256 | 12.394 / 0.248 |
Transfer [Kbytes/sec] | 5718.29 | 3381.53 | 3495.28 |
Źródło: opracowanie własne
Włączenie opcji keep-alive dało jeszcze lepsze rezultaty, z obsługiwanych 2743 żadań na sekundę ich ilość wzrosła do 6586 żadań. Takiego rezultaty nie udało się uzyskać w innych przeprowadzonych testach (przy takiej ilości zapytań).
Można stwierdzić, ze autorzy nie uprawiają propagandy na stronie domowej projektu, wydajność oprogramowania jest naprawdę imponująca.
Na poniższych wykresach przedstawione jest również pierwsze 100 żądań i czas odpowiedzi na te żądania dla opcji z i bez keep-alive:
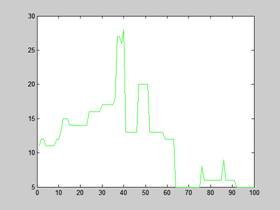
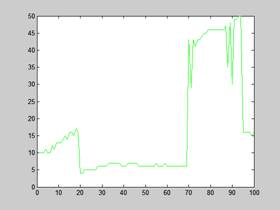
PERL (KLASTER) | PERL (komputer 6) |
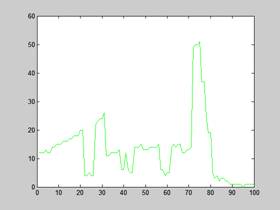
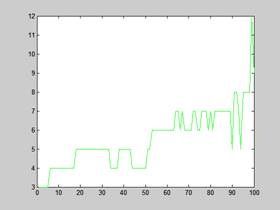
PERL (komputer 5) | PERL (KLASTER) – keep-alive |
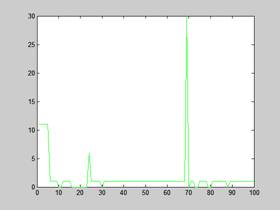
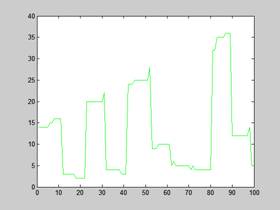
PERL (komputer 6) – keep-alive | PERL (komputer 5) – keep-alive |
Rysunek 10 – Czas odpowiedzi Varnish na pierwsze 100 żądań
Maksymalne wychylenie czasu oczekiwania dla klastra jak pokazują wykresy to niecałe 30 ms, czas oczekiwania jest zmienny, natomiast w przypadku poprzednich badań czas prostoliniowo wzrastał. Pseudo liniowość możemy zauważyć dopiero przy włączeniu opcji keep-alive, ale w tym przypadku czas wynosi zaledwie 12 ms.
Wykres dla całego przeprowadzonego testu bez włączonej opcji keep-alive pokazuje prawie równomierny czas odpowiedzi mieszczący się w granicach normy z niewielkimi odchyleniami porównując do testu wydajności samego serwera WWW dla treści statycznej. Wykres kończy się na wartości 120, co pokazuje, że klaster nie był zbyt mocno obciążony tak jak w przypadku klastra z serwerem WWW, gdzie wykres kończył się na wartości 300ms.
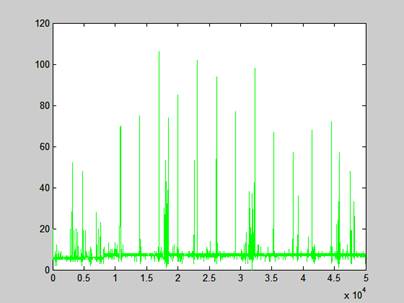
Rysunek 11 - Czas odpowiedzi Varnish dla wszystkich próbek
Wykres z opcją keep-alive pokazuje jeszcze dobitniej inżynierię projektantów systemu, czas odpowiedzi nie przekracza średnio 6ms pomijając kilka wartości skrajnych.
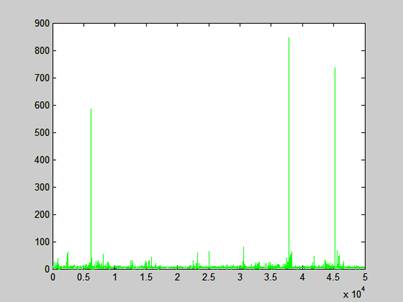
Rysunek 12 - Czas odpowiedzi Varnish dla wszystkich próbek (keep-alive)
Wydajność treści statycznej w zależności od konfiguracji serwera WWW - HTML
Z reguły, najistotniejszy wpływ na wydajność systemu ma właściwe zestrojenie aplikacji obsługiwanych przez serwer WWW. Z drugiej strony odpowiednia konfiguracja samego serwera WWW może znacznie złagodzić niekorzystny wpływ źle zoptymalizowanych aplikacji, a także zapewnić wydajną rutynową pracę. Ponadto, odpowiednio wczesny trafny wybór odpowiednich ustawień parametrów Apache pozwala na uniknięcie kosztów rekonfiguracji.
Głównym parametrem poprawiającym znacznie wydajność serwera dla treści statycznych są opcje związane z KeepAlive, ponieważ narzut związany z inicjowaniem każdego połączenia http spowodowałoby istotne wydłużenie czasu całkowitego pobierania strony. Aby właśnie rozwiązać ten problem, zostały opracowane mechanizmy KeepAlive i "potoków" żądań. Idea nie jest skomplikowana - jedno połączenie http powinno być wykorzystywane do przekazywania wielu żądań od tego samego klienta. Efektywne wykorzystanie tego mechanizmu pozwala na radykalne skrócenie czasu pobierania strony.
Natomiast opcja KeepAliveTimeout definiuje czas ważności gniazda, wyznacza czas oczekiwania serwera na dosłanie przez klienta kolejnego żądania, a parametr Timeout określa czas trwania połączenia.
Dyrektywa MaxKeepAliveRequests definiuje maksymalną liczbę żądań, która może zostać przesłana do serwera w czasie trwania połączenia (opcja KeepAlive musi być włączona). Po odebraniu maksymalnej liczby żądań proces zostaje zakończony, a nowe zestawione połączenie klienckie jest obsługiwane przez nowy proces potomny Apache[8].
Dyrektywy MinSpareServers i MaxSpareServers pozwalają na utrzymanie odpowiedniej liczby procesów potomnych przez eliminację procesów bezczynnych. Są dosyć istotnymi parametrami dla obsługi chwilowego wzrostu natężenia ruchu.
Jednym ze sposobów na obniżenie traffica generowanego przez klientów jest kompresja stron, która w przypadku stron statycznych daje bardzo dobre rezultaty:
Tabela 13 - Treść statyczna, wyniki dla stron testowych skompresowanych i bez kompresji
KOMPUTER | KOMP 4 | ||
Strona | bez kompresji (bajtów) | z kompresją (bajtów) | współczynnik |
index.html | 169 | 132 | 78% |
test.php | 93 | 80 | 86% |
phpinfo.php | 55868 | 9660 | 17% |
index.html (strona CIDE) | 6821 | 2217 | 32% |
mater.html (strona CIDE) | 65864 | 9574 | 14% |
index.html (strona ONET.pl) | 126237 | 23837 | 18% |
Źródło: opracowanie własne
Im bardziej obszerna w tekst strona tym większe "upakowanie", dla strony Onetu współczynnik kompresji wyniósł 18%, to jest 5 krotne zmniejszenie niezbędnej przepustowości łącza i szybsze dostarczenie treści do odbiorcy. Najdobitniej pokazują to poniższe testy wykonane dla 4000 zapytań (40 zapytań na sekundę):
Tabela 14 - Treść statyczna HTML z kompresją i bez
KOMPUTER | KOMP 4 | |
Sposób wykonywania skryptu | bez komp. | z komp. |
Rozmiar transferowany (bajtów) | 126499 | 23910 |
Czas testu [s] | 59.616918 | 13.133833 |
Odebranych bajtów (całość) | 507361128 | 97257440 |
Odebranych bajtów (HTML) | 506228562 | 96037562 |
Żądań na sekundę | 67.10 | 304.56 |
Czas na żądanie [ms] | 596.169 / 14.904 | 131.338 / 3.283 |
Transfer [Kbytes/s] | 8310.88 | 7231.48 |
Źródło: opracowanie własne
Jak widać wykorzystanie kompresji dało w badanym przypadku 4.5 krotne skrócenie czasu, ilość obsługiwanych żądań na sekundę zwiększyła się o 234,46.
Konfiguracja modułu deflate przedstawia się następująco:
LoadModule deflate_module modules/mod_deflate.so
AddOutputFilterByType DEFLATE application/x-httpd-php
AddOutputFilterByType DEFLATE application/x-javascript
AddOutputFilterByType DEFLATE application/xhtml+xml
AddOutputFilterByType DEFLATE image/svg+xml
AddOutputFilterByType DEFLATE text/css
AddOutputFilterByType DEFLATE text/html
AddOutputFilterByType DEFLATE text/plain
AddOutputFilterByType DEFLATE text/xml
Również efektowną metodą jest optymalizacja na poziomie protokołu http za pomocą modułu mod_expires związana głównie z obniżaniem poziomu ruchu i zmniejszaniem liczby zapytań, przy czym wykorzystywane są nagłówki buforu (ang. caching header). Nagłówki buforu mówią klientowi (np. przeglądarce WWW), że nie ma potrzeby ponownego pobierania przez określony czas pewnej części danych. Nagłówek Expires wskazuje, kiedy dokument powinien zostać ponownie pobrany. Poniższej przedstawiona jest konfiguracja modułu mod_expires z ustawionym dla plików graficznym, css i skryptów javascript 5 godzinnym odświeżaniem
LoadModule expires_module modules/mod_expires.so
ExpiresActive on
ExpiresByType image/gif "access plus 5 hours 3 minutes"
ExpiresByType image/png "access plus 5 hours 3 minutes"
ExpiresByType image/jpg "access plus 5 hours 3 minutes"
ExpiresByType image/ico "access plus 5 hours 3 minutes"
ExpiresByType text/javascript "access plus 5 hours 3 minutes"
ExpiresByType text/x-javascript "access plus 5 hours 3 minutes"
ExpiresByType text/css "access plus 5 hours 3 minutes"
Jeszcze innym sposobem zwiększenia wydajności może być rekompilacja serwera WWW. Wiele popularnych dystrybucji zawiera pakiet Apache, skompilowany do pracy na procesorach serii 386 w celu zachowania kompatybilności.
Rekompilacji można dokonać ustawiając flagi kompilacji stosownie do posiadanej platformy sprzętowej. Jeśli serwer bazuje na procesorze Athlon, można użyć poniższego zestawu flag:
CFLAGS='-march=athlon U -fexpensive-optimizations -O3'
Flagi te wskazują kompilatorowi, żeby generował kod maszynowy działający wyłącznie na procesorach typu Athlon. W zamieszczonym przykładzie poziom optymalizacji jest ustawiony na 3, co pozwala kompilatorowi użyć zoptymalizowanych metod (kosztem dłuższego czasu kompilacji i kompatybilności). Dla przykładu wersja dla procesora Dual Xeon może wyglądać tak:
CFLAGS="-O3 -pipe -mcpu=pentium4 -march=pentium4 -fomit-frame-pointer"
Jeszcze innym sposobem optymalizacji może być ingerencja w pliki HTML. Pliki te posiadają największy potencjał optymalizacyjny. Znaczna część kodu HTML,
zwłaszcza przygotowywana dla serwisów firmowych i komercyjnych, jest dostarczana przez projektantów używających edytorów WYSIWYG, takich jak np. Dreamweaver.
Edytory te generują jednak dużo nadmiarowego kodu, który bardzo często można skrócić aż o 50 %, bez uszczerbku dla kodu. Generalnie zaleca się usuwanie możliwie wielu sekwencji formatujących z pliku HTML i umieszczanie ich w plikach arkuszy stylów CSS.
W odróżnieniu od sekwencji formatujących umieszczonych bezpośrednio w plikach HTML, pliki CSS są ładowane tylko raz, co oznacza, że serwer HTTP tylko raz wysyła sekwencje formatujące[5].
Wydajność treści dynamicznej w zależności od konfiguracji serwera WWW - PHP
PHP to język skryptowy zagnieżdżany wewnątrz znaczników HTML. W dużej mierze opiera się on na składni takich języków programowania, jak Java, C/C++ oraz Perl. Wielość modułów rozszerzających możliwości tego języka oraz fakt, iż jest on dostępny całkowicie za darmo, sprawiają, że PHP stał się jednym z najpopularniejszych narzędzi na rynku oprogramowania wykorzystywanego do tworzenia aplikacji internetowych. PHP pozwala również na wykonywanie skryptów z linii poleceń podobnie jak Perl i Python[1].
Ze względu na swoją naturę PHP jest ściśle zintegrowany z serwerem WWW. Standardowo skrypt jest załadowywany do pamięci, analizowany (parsowanie), a następnie kompilowany do kodu bajtowego, a po wykonaniu zwolniony z pamięci, dzięki czemu oferuje "na starcie" większą wydajność w porównaniu np. ze skryptami napisanymi w Perlu (gdzie dochodzi jeszcze załadowanie "silnika"). Niestety w przypadku bardziej rozbudowanych aplikacji również PHP staje się mało wydolny jak pokazują poniższe testy. Między innymi z tego względu powstały moduły rozszerzające PHP o cache'owanie kodu źródłowego skryptu w formie skompilowanej.
Takim modułem jest właśnie eAccelerator powstały na bazie Turck MMcache. Oferuje dynamiczne zarządzanie pamięcią podręczną skompilowanych kodów bajtowych oraz zakodowanych skryptów php. Po zainstalowaniu eAccelerator optymalizuje skompilowany kod bajowy i zapisuje go do pamięci oraz dodatkowo do pamięci współdzielonej lub na dysk.
Każde następne wywołanie danego skryptu powoduje natychmiastowe udostępnienie go przez akcelerator w gotowej, skompilowanej postaci, co pozwala uniknąć strat czasu na ponowną analizę i kompilację[14].
Instalacja modułu polega na skompilowaniu pobranego ze strony http://bart.eaccelerator.net/source/0.9.5.1/ kodu źródłowego, a następnie dodaniu wpisu w php.ini:
zend_extension="/usr/lib/php5/extensions/eaccelerator.so"
eaccelerator.shm_size="16"
eaccelerator.cache_dir="/tmp/eaccelerator"
eaccelerator.enable="1"
eaccelerator.optimizer="1"
eaccelerator.check_mtime="1"
eaccelerator.debug="0"
eaccelerator.filter=""
eaccelerator.shm_max="0"
eaccelerator.shm_ttl="0"
eaccelerator.shm_prune_period="0"
eaccelerator.shm_only="0"
eaccelerator.compress="1"
eaccelerator.compress_level="9"
Poniższe badania zostały wykonane dla 4000 zapytań w tym 25 jednocześnie, próby wykonania testu dla 25000 zapytań (w tym 50 jednocześnie) nie zakończyły się z powodu drastycznego obciążenia badanej maszyny w przypadku wyłączonego EA (load average powyżej 90). Test polegał na pobraniu przez ab strony startowej aplikacji phpMyAdmin w wersji 2.10.0.2.
ab -n 4000 -c 25 -k -g OPT233k.txt http://10.0.1.233/myadmin/index.php
Tabela 18 - Treść dynamiczna PHP - eAccelerator
KOMPUTER | KOMP 4 | |||
Sposób wykonywania skryptu | bez EA | z EA | ||
bez -k | z -k | bez -k | z -k | |
Czas testu [s] | 56.20924 | 54.24273 | 15.200460 | 15.276516 |
Żądań na sekundę | 71.40 | 74.04 | 263.15 | 261.84 |
Czas na żądanie [ms] | 350.131 / 14.005 | 337.652 / 13.506 | 95.003 / 3.800 | 95.478 / 3.819 |
Transfer [Kbytes/s] | 622.32 | 645.32 | 2293.55 | 2282.13 |
Źródło: opracowanie własne
Jak widać zastosowanie EA (eAccelerator) spowodowało skrócenie czasu i wzrost wydajności prawie czterokrotnie. Tak jak w przypadku treści dynamicznej - Perl tak i tutaj zastosowanie opcji keep-alive nie spowodowało znaczącego wzrostu wydajności (oszczędza się tutaj tylko na nawiązywaniu połączenia), w przypadku prawdziwego ruchu zastosowanie opcji keep-alive mogłoby nawet zmniejszyć drastycznie wydajność, gdyż w badanym przypadku zapytania były wykonywane tylko z jednej maszyny, natomiast w środowisku rzeczywistym zapytania pochodziłyby z różnych maszyn z różnym natężeniem.
Podsumowanie
Dziesięć lat temu sieć była dla wszystkich czymś ekscytującym. Dziś to już codzienność, narzędzie wszechobecne w życiu. Nawet małe firmy mają własne strony i serwery WWW. Coraz większe znaczenie w sieci odgrywa szybkość dostępu do informacji, a klienci są coraz mniej tolerancyjni na wszelkie trudności, wybierają te witryny, na których mogą szybko i łatwo znaleźć to, czego szukają. Optymalizacja wydajności serwerów WWW stała się ważniejsza niż kiedykolwiek wcześniej.
Zamierzeniem niniejszej pracy było sporządzenie optymalnej konfiguracji serwera WWW. Przebadano wpływ architektury maszyn na ich przepustowość, dzięki temu badaniu stwierdzono, że zastosowanie wydajniejszych komputerów może znacząco podnieść wydajność. Przeprowadzono testy z zastosowaniem klastra, gdzie pokazano, że zastosowanie pośredników buforujących może być znacznie wydajniejsze niż postawienie na klastrze serwerów WWW. Zanalizowano wpływ zmiany konfiguracji serwera WWW dla treści statycznej i dynamicznej uzyskując diametralną poprawę wydajności przy zastosowaniu "dopalaczy" w postaci np. eAccelarator'a. Sprawdzono również zużycie pamięci serwera WWW zależnie od wprowadzonych zmian w konfiguracji.
Zastosowanie wszystkich omówionych metod optymalizacji przedstawionych w niniejszej pracy powinny znacznie poprawić wizerunek serwisów prezentowanych na tak zoptymalizowanym serwerze WWW. Będzie to szczególnie dobrze widoczne w przypadku średnio i bardzo obciążonych serwerów. Przykładową zoptymalizowaną konfigurację na podstawie niniejszych badań zawiera załącznik. W załączniku została przedstawiona konfiguracja modułów serwera Apache takich jak mod_perl, php, deflate czy expires.
Cel pracy został osiągnięty, ponadto zaprezentowane metody zostały wdrożone między innymi przy konfiguracji nowego serwera Biblioteki Głównej US obsługującej system biblioteczny oraz stronę domową biblioteki, a także w holenderskim sklepie internetowym Lubera specjalizującym się w sprzedaży wysyłkowej kwiatów, nasion i innych produktów związanych z ogrodnictwem.
BIBLIOGRAFIA
1. Choi Wankyu, Kent Allan, Lea Chris, Gane, "PHP4 od podstaw", Helion, Warszawa 2001
2. Geoffrey Young, Paul Lindner, Randy Kobes, . "mod_perl. Podręcznik programisty", Helion, Warszawa 2003
3. Jia Wang, "A survey of web caching schemes for the Internet". ACM SIGCOMM Computer Communication Review, 1999, vol. 29, no 5, pp. 36-46
4. Lal Kazimierz, Rak Tomasz, "Linux a technologie klastrowe", Wydawnictwo MIKOM, Warszawa 2005
5. Pfaffenberger Bryan, Karow Bill, "HTML 4. Biblia", Helion, Warszawa 2001
6. Randal L. Schwartz, Tom Christiansen, "Perl. Wprowadzenie", Helion, Warszawa 2000
7. Ridruejo Daniel Lopez, Liska Allan, "Apache. Podręcznik administratora", RMIKOM, Warszawa 2002
8. Ryan C. Barnett, "Apache. Zabezpieczenie aplikacji i serwerów WWW", Helion, Warszawa 2007
9. Tadeusz Wilczek, "Przybyli Apacze pod okienka". PCkurier. Grudzień 2001, nr 25,
s. 6-7
10. Valeria Cardellini, Emiliano Casalicchio, Michele Colajanni, Philip S. Yu, "The state of the art in locally distributed Web-server systems", ACM Computing Surveys (CSUR), 2002, vol. 34, no 2, pp. 263-311
11. Wessels Duane, "Web caching - optymalizacja dostępu", Wydawnictwo RM, Warszawa 2002
12. William von Hagen, Brian K. Jones, "100 sposobów na Linux Server. Wskazówki i narzędzia dotyczące integracji, monitorowania i rozwiązywania problemów", Helion, Warszawa 2007
Źródła internetowe:
13. „July 2007 Web Server Survey” [dostęp: 1 sierpnia 2007]. Dostępny w Internecie: http://news.netcraft.com/archives/2007/07/09/july_2007_web_server_survey.html
14. „eAccelerator – Install from Skurce” [dostęp: 1 sierpnia 2007]. Dostępny w Internecie: http://eaccelerator.net/wiki/InstallFromSource
15. Poul-Henning Kamp, „ArchitectNotes”, 2006 [dostęp: 1 sierpnia 2007]. Dostępny w Internecie: http://varnish.projects.linpro.no/wiki/ArchitectNotes
SPIS RYSUNKÓW
Rysunek 1 - Schematyczna struktura wybranych elementów sieci BG (źródło: opracowanie własne)
Rysunek 2 - Schemat budowy klastra
Rysunek 3 - Czas odpowiedzi klastra na pierwsze 100 żądań dla różnych algorytmów szeregowania
Rysunek 4 - Czas odpowiedzi na pierwsze 100 żądań klastra oraz komputera nr 5 (treść statyczna)
Rysunek 5 - Czas odpowiedzi na pierwsze 100 żądań klastra oraz komputera nr 6 (treść statyczna)
Rysunek 6 - Czas odpowiedzi na piersze 100 żądań komputera 5 i 6 (opcja keep-alive)
Rysunek 7 – Czas odpowiedzi klastra oraz komp. wchodzących w skład klastra na pierwsze 100 żądań (treść dynamiczna – PERL)
Rysunek 8 - Czas odpowiedzi HTML dla wszystkich próbek
Rysunek 9 - Czas odpowiedzi dla wszystkich próbek HTML (keepalive)
Rysunek 10 – Czas odpowiedzi Varnish na pierwsze 100 żądań
Rysunek 11 - Czas odpowiedzi Varnish dla wszystkich próbek
Rysunek 12 - Czas odpowiedzi Varnish dla wszystkich próbek (keep-alive)
SPIS TABEL
Tabela 1 - Treść statyczna HTML bez opcji keep-alive
Tabela 2 - Treść statyczna HTML z opcją keep-alive
Tabela 3 - Treść statyczna HTML na łączu 1Gbit
Tabela 4 - Treść statyczna HTML na łączu 1 Gbit (keep-alive)
Tabela 5 - Treść dynamiczna PERL (keep-alive)
Tabela 6 - Wyniki dla treści statycznej HTML dla różnych algorytmów szeregowania
Tabela 7 - Wyniki dla treści statycznej HTML dla różnych algorytmów szeregowania z opcją keep-alive
Tabela 8 - Wyniki dla treści statycznej HTML dla klastra, komputera 5 i 6
Tabela 9 - Treść dynamiczna PHP
Tabela 10 - Treść dynamiczna PERL (mod_cgi)
Tabela 11 - Treść dynamiczna - surogata (bez opcji keep-alive)
Tabela 12 - Treść dynamiczna - surogata (z opcją keep-alive)
Tabela 13 – Treść statyczna, wyniki dla stron testowych skompresowanych i bez kompresji
Tabela 14 - Treść statyczna HTML z kompresją i bez
Tabela 15 - Treść dynamiczna PERL - CGI vs mod_perl
Tabela 16 - Treść dynamiczna PERL, CGI vs mod_perl (skrypt z wyk. modułów CGI i Template)
Tabela 17 - Treść dynamiczna PERL, porównanie CGI, PerlRun i Registry
Tabela 18 - Treść dynamiczna PHP - eAccelerator
Tabela 19 - Wyniki dla pierwszego Apache
Tabela 20 - Wyniki dla następnych Apache
Tabela 21 - Sumaryczne zużycie pamięci Apache.
Tabela 22 - Sumaryczne zużycie pamięci Apache po obciążeniu
Tabela 23 - Sumaryczne zużycie pamięci Apache w czasie obciążenia